Latent Agents: A Post-Training Procedure for Internalized Multi-Agent Debate
ACL'26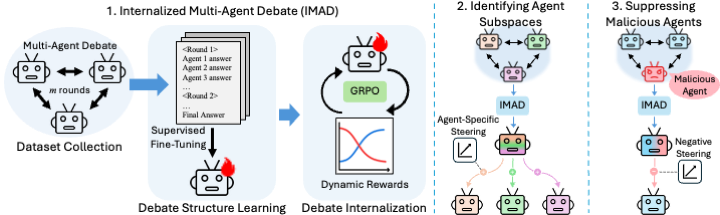
TL;DR
We introduce IMAD (Internalized Multi-Agent Debate), a two-stage fine-tuning pipeline that distills multi-agent debate into a single model, matching or exceeding explicit debate while using up to 93% fewer tokens. We further show that internalization creates interpretable, controllable agent-specific subspaces in activation space, which can even be steered to suppress malicious agents.
Abstract
Multi-agent debate has been shown to improve reasoning in large language models (LLMs). However, it is compute-intensive, requiring generation of long transcripts before answering questions. To address this inefficiency, we develop a framework that distills multi-agent debate into a single LLM through a two-stage fine-tuning pipeline combining debate structure learning with internalization via dynamic reward scheduling and length clipping. Across multiple models and benchmarks, our internalized models match or exceed explicit multi-agent debate performance using up to 93% fewer tokens. We then investigate the mechanistic basis of this capability through activation steering, finding that internalization creates agent-specific subspaces: interpretable directions in activation space corresponding to different agent perspectives. We further demonstrate a practical application: by instilling malicious agents into the LLM through internalized debate, then applying negative steering to suppress them, we show that distillation makes harmful behaviors easier to localize and control with smaller reductions in general performance compared to steering base models. Our findings offer a new perspective for understanding multi-agent capabilities in distilled models and provide practical guidelines for controlling internalized reasoning behaviors.
IMAD: Internalized Debate
IMAD distills the full multi-agent debate process into a single model through a two-stage fine-tuning pipeline. We first collect debate traces using the standard multi-agent debate protocol (3 agents over 2 rounds) on arithmetic problems, tagging each transcript with structure markers for agents, rounds, and consensus.
Stage 1: Debate structure learning (SFT)
We supervise-fine-tune the base model on the full debate traces, not just the final answers, so it learns to reproduce the multi-round, multi-agent debate format on its own.
Stage 2: Debate internalization (RL)
We then apply GRPO with a dynamic reward that gradually moves the model from explicit debate to implicit reasoning. A formatting reward for emitting the debate tags is decayed toward zero, while a correctness reward with length clipping shrinks the allowed output (2000 down to 500 tokens) so the correct answer must appear earlier and earlier. As verbalizing the debate becomes incompatible with the shrinking length budget, the model learns to run the debate internally and emit only the final answer.
Results
We evaluate IMAD on GSM8K, MMLU-Pro, and BigBench-Hard across three open-weight base models. IMAD matches or exceeds explicit debate while using only a small fraction of its tokens (6 to 21%, a 5 to 16x efficiency gain), and it generalizes to these benchmarks despite being trained only on arithmetic. Use the arrows to switch between base models. All numbers are mean accuracy and average token consumption (input plus output) per question across three runs.
| Method | Accuracy (%) | Avg. Tokens | ||||
|---|---|---|---|---|---|---|
| GSM8K | MMLU-Pro | BBH | GSM8K | MMLU-Pro | BBH | |
| Single | 79.93 | 61.10 | 56.37 | 547 | 638 | 463 |
| Debate | 83.03 | 64.60 | 51.06 | 5758 | 8705 | 8888 |
| DebateGPT | 74.42 | 60.58 | 55.83 | 455 | 1023 | 433 |
| SFT | 79.23 | 75.60 | 54.91 | 992 | 1447 | 1133 |
| IMAD | 85.20 | 62.00 | 58.53 | 644 | 728 | 563 |
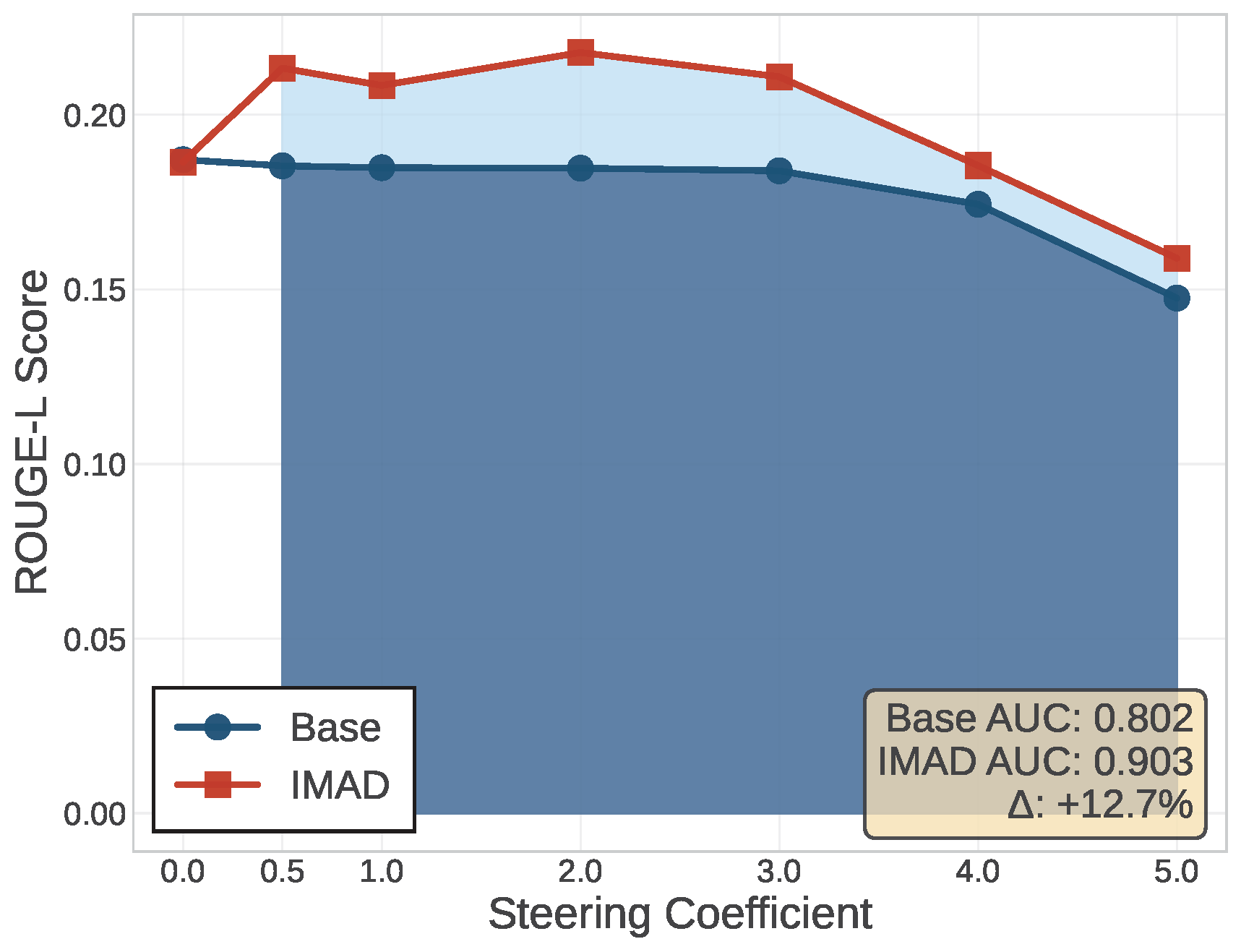
Agent Subspaces
Does internalization collapse the agents into undifferentiated reasoning, or do individual agents persist? To find out, we distill debates with three distinct personas (Chain-of-Thought, Self-Critique, and Program-of-Thought), then extract per-agent steering vectors via difference-in-means (Contrastive Activation Addition) and add them back at inference.
Measuring ROUGE-L alignment between steered outputs and ground-truth agent responses, IMAD is consistently more steerable toward each agent than the base model (AUC 0.903 vs. 0.802, a 15.4% average improvement across agents). This indicates that internalization preserves the collaborative structure of debate as linearly separable agent subspaces rather than collapsing it.
Controlling Agent Behavior
Agent subspaces are not only interpretable, they are controllable. We train IMAD on debates where one agent is deliberately malicious (either evil intent or hallucination), then suppress that agent with negative steering, comparing against an identically steered base model.
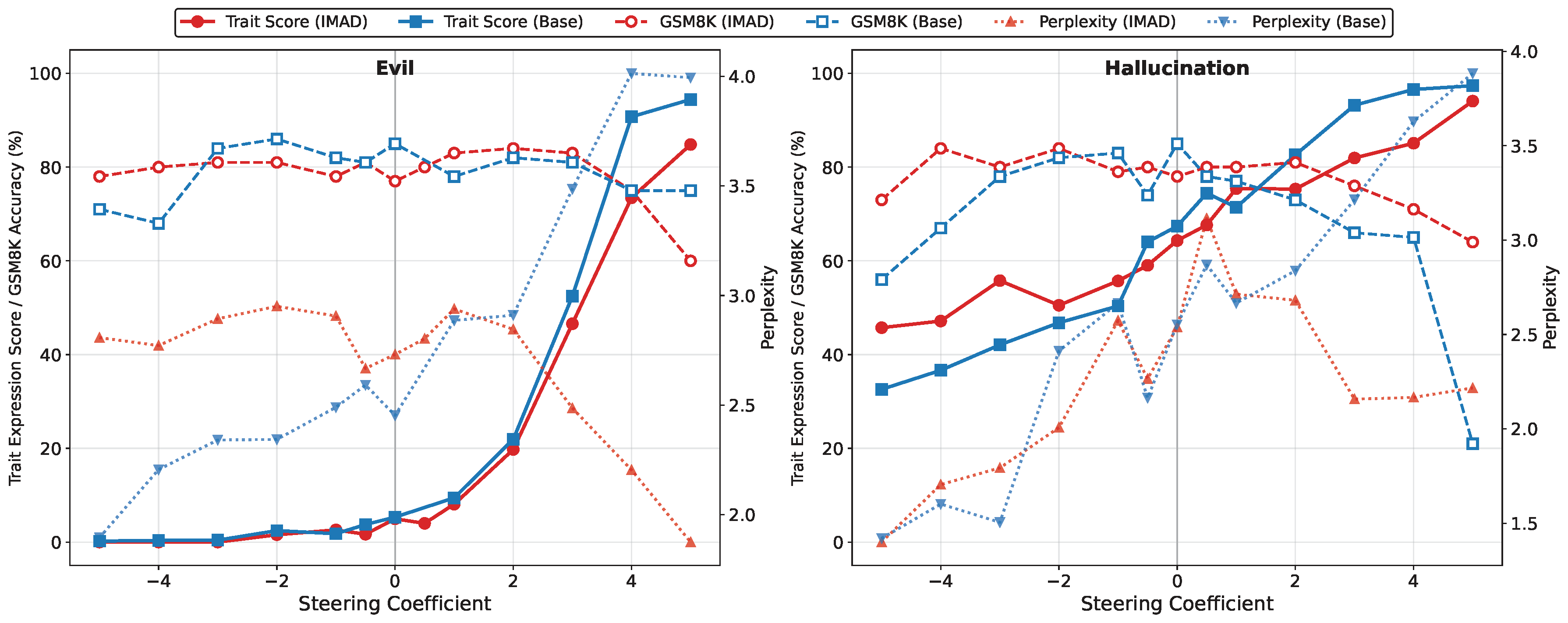
- For the evil trait, IMAD reaches complete suppression (trait score to 0) under strong negative steering, while the base model retains residual malicious behavior.
- Hallucination is more distributed and only partially suppressible, but both models suppress it monotonically as the coefficient decreases.
- Crucially, IMAD preserves task performance (GSM8K) across the full steering range, whereas the base model degrades and collapses at extreme coefficients.
Internalization makes harmful behaviors easier to localize and remove with less collateral damage, a practical benefit for LLM safety.
Takeaways
- A two-stage pipeline, SFT followed by RL with a decaying format reward and length clipping, drives the shift from explicit debate to internal reasoning.
- Although trained only on arithmetic, IMAD generalizes to math, multi-domain knowledge, and diverse reasoning benchmarks.
- Internalization preserves debate as linearly separable agent subspaces that can be recovered through activation steering.
- These subspaces are controllable: malicious agents can be suppressed via negative steering with little damage to general task performance.
Citation
@inproceedings{yi2026latent,
title = {Latent Agents: A Post-Training Procedure for Internalized Multi-Agent Debate},
booktitle = {Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL)},
author = {Yi, John Seon Keun and Mueller, Aaron and Lee, Dokyun},
year = {2026},
}
powered by Academic Project Page Template